Giriş: Python, veri analizi ve manipülasyonunda geniş bir format yelpazesi sunar. Ancak, hangi veri depolama formatının seçileceği, projenin özelliklerine ve gereksinimlerine bağlıdır. Bu yazıda, Excel, CSV, HDF5, JSON, Parquet ve Pickle formatlarını boyut, hız ve okunabilirlik açısından analiz edeceğiz.
Excel (.xlsx) Dosyaları:
- Boyut: Genellikle büyük boyutlara sahip, özellikle büyük veri setleriyle kullanıldığında.
- Hız: Diğer formatlara göre açma ve işleme süreçleri daha yavaş olabilir.
- Okunabilirlik: İnsanlar tarafından okunabilir ve düzenlenebilir.
CSV (Comma-Separated Values) Dosyaları:
- Boyut: Genellikle diğer formatlara göre daha küçük boyutlara sahiptir.
- Hız: Hızlı açılabilir ve işlenebilir.
- Okunabilirlik: İnsanlar tarafından okunabilir ve düzenlenebilir.
HDF5 (Hierarchical Data Format version 5) Dosyaları:
- Boyut: Sıkıştırma ve sütun tabanlı depolama nedeniyle diğer formatlara göre küçük boyutlara sahip olabilir.
- Hız: Büyük veri setleriyle çalışırken hızlı açılabilir ve işlenebilir.
- Okunabilirlik: İnsanlar tarafından okunabilir değildir, ancak veri setleri için optimize edilmiştir.
JSON (JavaScript Object Notation) Dosyaları:
- Boyut: Diğer formatlara göre genellikle daha büyük boyutlara sahiptir.
- Hız: Açılma ve işlenme süreçleri diğer formatlara göre daha yavaş olabilir.
- Okunabilirlik: İnsanlar tarafından okunabilir ve düzenlenebilir.
Parquet Dosyaları:
- Boyut: Sıkıştırma ve sütun tabanlı depolama nedeniyle diğer formatlara göre küçük boyutlara sahip olabilir.
- Hız: Büyük veri setleriyle çalışırken hızlı açılabilir ve işlenebilir.
- Okunabilirlik: İnsanlar tarafından okunabilir değildir, ancak veri setleri için optimize edilmiştir.
Pickle (.pkl) Dosyaları:
- Boyut: Genellikle küçük boyutlara sahiptir ve Python nesnelerini depolamak için kullanılır.
- Hız: Python’un doğal veri tipini doğrudan depolar, bu nedenle hızlıdır.
- Okunabilirlik: İnsanlar tarafından okunabilir değildir ve sadece Python’da kullanılabilir.
YÜK TESTİ
Aşağıdaki örnekte, her format için yazma ve okuma süreleri 100.000 satırlık rastgele bir veri kümesi üzerinde ölçülecektir.
import time
import pandas as pd
from faker import Faker
# Faker nesnesini oluştur
fake = Faker()
# Rastgele veri kümesi oluştur
data = {'Name': [fake.name() for _ in range(100000)],
'Age': [fake.random_int(min=18, max=99, step=1) for _ in range(100000)],
'City': [fake.city() for _ in range(100000)]}
df = pd.DataFrame(data)
# Excel yazma ve okuma süreleri
start_time = time.time()
df.to_excel('sample_large_excel.xlsx', index=False)
excel_write_time = time.time() - start_time
start_time = time.time()
df_excel = pd.read_excel('sample_large_excel.xlsx')
excel_read_time = time.time() - start_time
# CSV yazma ve okuma süreleri
start_time = time.time()
df.to_csv('sample_large_csv.csv', index=False)
csv_write_time = time.time() - start_time
start_time = time.time()
df_csv = pd.read_csv('sample_large_csv.csv')
csv_read_time = time.time() - start_time
# Parquet yazma ve okuma süreleri
start_time = time.time()
df.to_parquet('sample_large_parquet.parquet', index=False)
parquet_write_time = time.time() - start_time
start_time = time.time()
df_parquet = pd.read_parquet('sample_large_parquet.parquet')
parquet_read_time = time.time() - start_time
# Pickle yazma ve okuma süreleri
start_time = time.time()
df.to_pickle('sample_large_pickle.pkl')
pickle_write_time = time.time() - start_time
start_time = time.time()
df_pickle = pd.read_pickle('sample_large_pickle.pkl')
pickle_read_time = time.time() - start_time
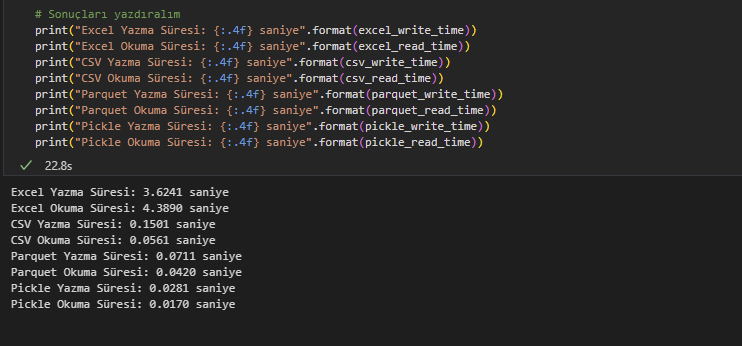
# Sonuçları yazdıralım
print("Excel Yazma Süresi: {:.4f} saniye".format(excel_write_time))
print("Excel Okuma Süresi: {:.4f} saniye".format(excel_read_time))
print("CSV Yazma Süresi: {:.4f} saniye".format(csv_write_time))
print("CSV Okuma Süresi: {:.4f} saniye".format(csv_read_time))
print("Parquet Yazma Süresi: {:.4f} saniye".format(parquet_write_time))
print("Parquet Okuma Süresi: {:.4f} saniye".format(parquet_read_time))
print("Pickle Yazma Süresi: {:.4f} saniye".format(pickle_write_time))
print("Pickle Okuma Süresi: {:.4f} saniye".format(pickle_read_time))
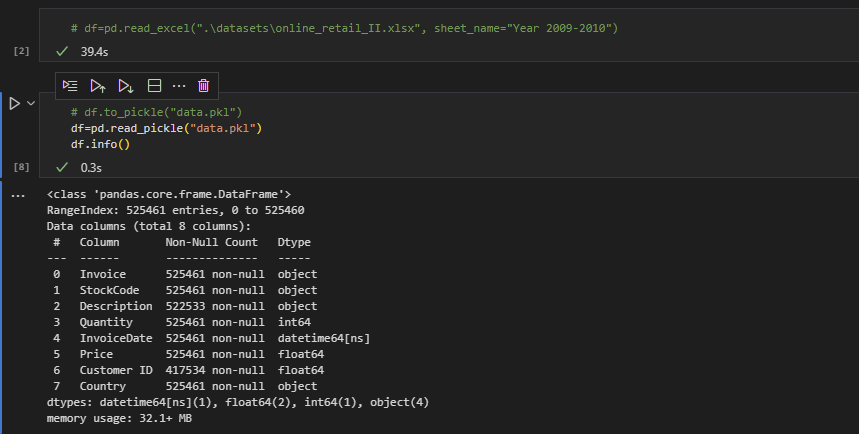
Python’da pandas kütüphanesi üzerinden Excel dosyalarını okuma işlemleri, özellikle büyük dosyalarla çalışırken yavaşlık sorunlarına neden olabilir. Bu durumun birkaç nedeni var:
- Dosya Biçimi: Excel dosyalarının .xlsx gibi yeni biçimleri genellikle daha hızlı okunabilirken, eski .xls biçimleri daha yavaş.
- Veri Tipi Tanıma: Pandas, her sütunun veri türünü otomatik olarak belirlemeye çalışır. Büyük veri setlerinde bu işlem çok daha uzun.
- Bellek Kullanımı: Büyük dosyaların bellekte tutulması, sistem belleği sınırlamalarına takılabilir.
- Optimizasyon Sorunları: Pandas’ın belirli durumlar için optimize edilmemiş olabilir.
- Diğer İşlemler: Veriyi okuma işlemi, diğer işlemlerle (filtreleme, sıralama, gruplama vb.) birleştirildiğinde daha da yavaşlayabilir.
Gerçek bir veri setinden örnek vermek gerekirse; aşağıdaki örneğimizde 520K satırlı bir excel dosyasını 40 saniyede okurken, pickle formatlı bir dosyayı sadece 0.3 saniyede okuyabildiğimizi gözlemleyebilirsiniz. Tamamen Python üzerinde kullanacak iseniz, ilk okuma sonrasında dosyanızı pickle olarak kaydedip sonra çalışmaya başlamanızı tavsiye ederim.