

“26B ve 31B modeller, kendi büyüklüklerinin çok ötesinde bir performans sergileyerek hem rakiplere hem de sahada ne kadar fazla donanıma ihtiyaç duyulduğuna dair alışkanlıkları sarsıyor.“
Google DeepMind, dün gece Gemma 4’ü duyurdu. Açık ağırlıklı model ailesi olarak tanımlanan bu sürüm, başlığındaki “byte byte en yetenekli” iddiasını yalnızca bir pazarlama sloganı olarak değerlendirmemek gerekiyor. Çünkü ardındaki rakamlar, en azından belirli boyutlarda, bu iddiayı destekliyor.
Bu yazıda pratik açıdan asıl ilgi çekici olanları, yani 26B MoE ve 31B Dense modelleri ele alıyoruz. Telefonda ya da küçük cihazlarda çalışan E2B/E4B değil; gerçek bir çıktı kalitesi arayışındaki geliştirici ve kurumlar için tasarlanmış, sunucu ya da yüksek performanslı tüketici GPU’larında koşan versiyonlar bunlar.
Rakipler karşısında nerede duruyorlar?
Açık model ekosisteminde ilk çeyrek 2026, özellikle Çinli laboratuvarların çıktılarıyla son derece hareketli geçti. Gemma 4’ün bu tablodaki yeri şu benchmark’larla okunabilir — ve önceki nesille karşılaştırıldığında fark, küçümsenmeyecek boyutta:

Bu üç test sırasıyla derin matematik muhakemesi, doktora düzeyi bilimsel akıl yürütme ve gerçek dünya kodlama kapasitesini ölçüyor. Gemma 3 27B bu testlerde sırasıyla yüzde 20.8, 42.8 ve 29.1 almıştı. Nesiller arası fark, kademeli bir iyileşme değil; neredeyse farklı bir model kategorisine geçiş anlamına geliyor.
Arena AI sıralamasına göre 31B, tüm açık modeller arasında üçüncü sırada; 26B MoE ise altıncı. Bu sonuçların ne anlama geldiğini anlamak için bir referans: 26B MoE, çıkarım sırasında toplam parametrelerinin yalnızca 3.8 milyarını aktive ediyor. Yani erişim hızı ve donanım maliyeti açısından çok daha küçük bir model gibi davranırken kalite sıralamasında devlerle yarışıyor.
“Gemma 3 27B bu testlerde yüzde 20–29 bandında kalırken, Gemma 4 31B yüzde 80–89’a ulaştı. Bu nesiller arası bir sıçrama değil, kategori değişimi.”
Dört boyutta ne değişti?
Halüsinasyon
Thinking modu aktifken (adım adım akıl yürütme) belirgin biçimde düşüyor. Gemma 3’ün BigBench Extra Hard skoru yüzde 19.3’tü; 31B bu testte yüzde 74.4 aldı. Doğrudan bir halüsinasyon metriği olmasa da yoğun bilgi gerektiren sorularda bu fark okunabilir. Thinking kapalıyken küçük modellerle temkinli olmak gerekiyor.
Hard Prompt
Native system prompt desteği ve güçlendirilmiş hizalama, önceki nesle kıyasla ciddi bir güvenlik iyileştirmesi sunuyor. Ancak Apache 2.0 ile yayınlanan her açık modelde olduğu gibi, ağırlıklara doğrudan erişim beyaz kutu saldırılarını kalıcı bir risk olarak barındırıyor. API üzerinden kullanımda direnç güçlü.
Çoklu Görev
31B modelde 256K token context window, hibrit attention mimarisi ve native function calling birleşince çok adımlı ajan görevlerinde tutarlılık önemli ölçüde artıyor. Özellikle tanımlı araç pipeline’larında Gemma 3’e kıyasla gözle görülür bir stabilite farkı var.
Ajan & Sınıf.
Bu alanda en çarpıcı sıçrama burada: Gemma 3 27B, τ²-Bench çok adımlı araç kullanımı testinde yüzde 6.6 alırken Gemma 4 31B yüzde 86.4’e ulaştı. Bunun nedeni function calling’in artık instruction-following ile zorla sağlanmak yerine doğrudan modele eğitim aşamasında yerleştirilmesi. Niyet anlama, kategorizasyon ve sınıflandırma görevlerinde bu fark doğrudan çıktı kalitesine ve JSON tutarlılığına yansıyor.
Rakip manzarası
Gemma 4’ü bu kalabalık tabloya yerleştirmek gerekirse: kendi ağırlık sınıfında en iyisi,
ama “her şeyin en iyisi” değil.
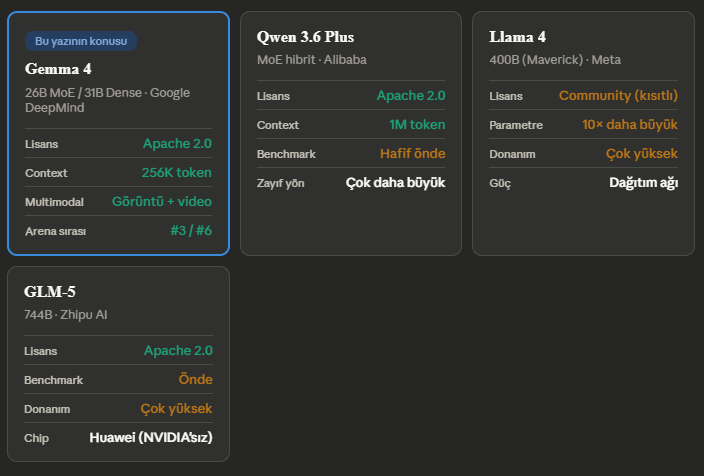
Tablonun söylediği şu: Qwen 3.6 Plus ve GLM-5, belirli benchmark’larda Gemma 4’ün önünde. Ama her iki model de ya çok daha büyük parametre sayısına ya da çok daha yüksek donanım gereksinimine ihtiyaç duyuyor. Gemma 4’ün asıl iddiası performans/parametre oranında: tek bir H100 GPU’ya sığıyor, tüketici GPU’larında quantize versiyonlarla çalışıyor ve Apache 2.0 ile herhangi bir ticari kısıt taşımıyor.
Llama 4 ise farklı bir oyun oynuyor — Meta’nın güçlü dağıtım ağı ve çok daha büyük parametre havuzu ile gelişmiş akıl yürütme görevlerini hedefliyor. Ama community lisansının getirdiği kısıtlamalar ve erişim eşiği, kurumsal bağımsız dağıtımda Gemma 4’ün gerisinde kalmasına neden oluyor.
Kim için gerçekten anlamlı?
Kendi altyapısında model çalıştırmak isteyen ve büyük bir donanım bütçesi olmayan her geliştirici ve kurum için Gemma 4 somut bir seçenek haline geldi. Bunun üç temel nedeni var: Apache 2.0 lisansı ticari kullanımın önündeki tüm engelleri kaldırıyor; 31B model tek bir H100’e sığıyor; ve Ollama, llama.cpp, Hugging Face üzerinden sıfırıncı günde erişilebilir durumda.
Ajan iş akışları ve yapılandırılmış sınıflandırma görevleri için ise tablo özellikle ilgi çekici: function calling’in modelin içine eğitilmesi, prompt mühendisliği yükünü azaltıyor ve çok adımlı görevlerde öngörülemeyen çıktı riskini düşürüyor. Bu, içgörü üretimi ve otomasyona dayalı iş akışları kuran ekipler için doğrudan verimlilik anlamına taşıyor.
Kapanış
Gemma 4’ün 26B ve 31B modelleri, açık model ekosisteminde verimlilik çıtasını belirgin biçimde yükseltti. Kendi boyutlarını aşan benchmark performansları, Apache 2.0 lisansı ve geniş ekosistem desteğiyle birleşince bu modeller yalnızca akademik değil, endüstriyel ölçekte de dikkate alınması gereken birer seçenek haline geldi. Ajan ve sınıflandırma tarafındaki nesil sıçraması ise bu modeli yalnızca “iyi bir açık model” değil, belirli kullanım senaryolarında tercih edilebilir kılan asıl argüman.