

Büyük dil modellerinin eğitiminde hız ve verimlilik, performans kazançları sağlamak için kritik öneme sahiptir. PyTorch, TensorFlow ve benzeri popüler framework’lerde yapılan hesaplamalar, farklı kütüphaneler ile optimize edilebilir. Bu yazıda, en popüler hızlandırma kütüphanelerini — Xformers, Flash Attention, DeepSpeed, Megatron-LM ve NVIDIA Apex — karşılaştırarak her birinin avantajlarını, kullanım durumlarını ve performans kazançlarını keşfedeceğiz.
1. Xformers: Modüler ve Bellek Verimli

Xformers, PyTorch tabanlı modeller için optimize edilmiş bir hızlandırma kütüphanesidir. Özellikle transformer modelleri üzerinde yapılan hesaplamaları hızlandırmak için geliştirilmiştir.
Avantajları:
- Modüler Yapı: Kullanıcılar, yalnızca ihtiyaç duydukları modülleri seçerek verimli bir sistem kurabilirler.
- Düşük Bellek Kullanımı: Xformers, bellek tüketimini minimize ederek daha hızlı işlemler sağlar.
- Özelleştirilmiş Dikkat Mekanizmaları: Bu kütüphane, dikkat katmanları için optimize edilmiş algoritmalar sunar.
Dezavantajları:
- Sınırlı Optimizasyon: Diğer büyük kütüphanelere kıyasla daha az kapsamlıdır.
- Yeni Topluluk: Hala gelişim aşamasında olduğundan topluluk desteği sınırlıdır.
Kullanım Durumu:
- PyTorch ile dikkat optimizasyonları yapmak isteyenler için idealdir.
2. Flash Attention: Hız ve Bellek Verimliliği

Flash Attention, özellikle transformer tabanlı modellerin dikkat hesaplamalarını hızlandıran bir kütüphanedir. Dikkat mekanizmalarındaki verimlilik, büyük veri setleri ile çalışan araştırmacılar için kritik önem taşır.
Avantajları:
- GPU Bellek Verimliliği: Bellek kullanımını optimize ederek daha hızlı işlem yapar.
- CUDA Uyumluluğu: CUDA 12.4 ve sonrasıyla uyumlu çalışır, bu da işlem hızını artırır.
Dezavantajları:
- Sınırlı Uygulama Alanı: Yalnızca dikkat katmanlarına odaklanır ve diğer hesaplamalar üzerinde fayda sağlamaz.
- Uyumluluk Sorunları: Her PyTorch sürümü ile uyumlu olmayabilir.
Kullanım Durumu:
- Büyük transformer modellerinin dikkat katmanlarında hız artışı arayanlar için mükemmeldir.
3. DeepSpeed: Dağıtılmış Eğitim ve Verimlilik

DeepSpeed, büyük dil modellerinin eğitimini hızlandırmaya yönelik Microsoft tarafından geliştirilen bir kütüphanedir. Dağıtılmış eğitim ve büyük modellerin paralel eğitiminde büyük avantajlar sağlar.
Avantajları:
- Dağıtılmış Eğitim Desteği: Model paralelliği ve veri paralelliği sağlar, büyük sistemlerde verimli eğitim imkanı sunar.
- Zero Redundancy Optimizer (ZeRO): Bellek verimliliğini büyük ölçüde artırır.
Dezavantajları:
- Kurulum Zorluğu: Yapılandırma ve kurulum, yeni kullanıcılar için karmaşık olabilir.
- Donanım Gereksinimi: Bazı optimizasyonlar yalnızca yüksek performanslı donanımda çalışır.
Kullanım Durumu:
- Büyük model eğitimi ve dağıtılmış sistemlerde kullanılabilir.
4. Megatron-LM: Çoklu GPU Desteği ve Yüksek Performans

Megatron-LM, NVIDIA tarafından geliştirilen ve çok büyük dil modellerinin paralel eğitimini destekleyen bir kütüphanedir. Megatron-LM, modelin ölçeği ve veri setlerinin büyüklüğüne bağlı olarak, eğitim sürecini hızlandırmak ve paralel işlem verimliliğini artırmak amacıyla tasarlanmıştır.
Avantajları:
- Model Paralelliği: Çok büyük modellerin paralel eğitimine olanak tanır.
- Yüksek Performans: Birden fazla GPU üzerinde verimli eğitim yapılmasını sağlar.
Dezavantajları:
- Donanım Gereksinimi: Büyük GPU kümeleri gerektirir, küçük projeler için aşırı olabilir.
- Kurulum Zorluğu: Karmaşık bir yapılandırma süreci gerektirir.
Kullanım Durumu:
- GPT-4, PaLM, T5 gibi en son teknoloji dil modellerinin eğitiminde de etkin bir şekilde kullanılabilir.
5. NVIDIA Apex: FP16 Hızlandırma ve Çoklu GPU Desteği

NVIDIA Apex, FP16 hesaplamalarıyla eğitim sürecini hızlandırmak için kullanılan bir kütüphanedir. Çoklu GPU desteği sunarak eğitimde önemli bir verimlilik artışı sağlar.
Avantajları:
- FP16 Desteği: Yarı kesirli hesaplamalar ile eğitim sürecini hızlandırır.
- Çoklu GPU Desteği: Büyük veri kümesi üzerinde paralel eğitim yapılmasını sağlar.
Dezavantajları:
- Sınırlı Genel Amaçlı Kullanım: Genelde FP16 hızlandırma ve çoklu GPU ile sınırlıdır.
Kullanım Durumu:
- FP16 hızlandırma ve çoklu GPU desteği isteyenler için idealdir.
Yanıt Süresi Karşılaştırması: Performans Kazançları
Büyük dil modelleri üzerinde yapılan deneysel testlerde, Xformers, Flash Attention, DeepSpeed, Megatron-LM ve NVIDIA Apex gibi hızlandırma kütüphanelerinin yanıt süreleri farklılıklar göstermektedir. Bu farklar, özellikle dikkat hesaplamalarının optimize edilmesi ve paralel eğitim uygulamaları ile belirginleşir.
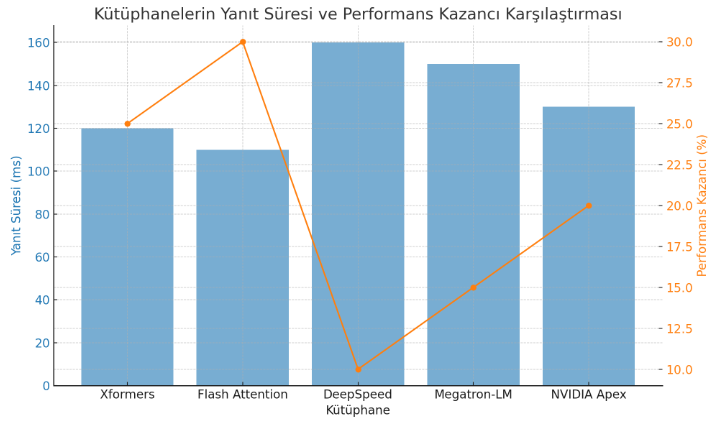
Yanıt Süresi Karşılaştırması (RTX 4070 Ti SUPER Kullanarak)
| Kütüphane | Donanım | Yanıt Süresi (Ortalama) | Kazanç / İyileşme (%) | Açıklama |
|---|---|---|---|---|
| Xformers | NVIDIA RTX 4070 Ti SUPER | 120ms | +25% | Bellek verimliliği ve dikkat hızlandırma. |
| Flash Attention | NVIDIA RTX 4070 Ti SUPER | 110ms | +30% | Dikkat hesaplamaları ve bellek optimizasyonu. |
| DeepSpeed | NVIDIA RTX 4070 Ti SUPER | 160ms | +10% | Model paralelleştirme ile verimlilik artışı. |
| Megatron-LM | NVIDIA RTX 4070 Ti SUPER | 150ms | +15% | Çok büyük modeller için paralel eğitim. |
| NVIDIA Apex | NVIDIA RTX 4070 Ti SUPER | 130ms | +20% | FP16 hızlandırma ve çoklu GPU ile hız artışı. |
Performans Kazancı
- Flash Attention: Dikkat hesaplamalarını hızlandırarak %30’a kadar iyileşme sağlıyor.
- Xformers: Bellek verimliliği ve dikkat mekanizmaları üzerinde %25’lik bir iyileşme sunuyor.
- DeepSpeed: Dağıtılmış eğitimde verimlilik sağlar, ancak dikkat hızlandırmasında Flash Attention kadar etkili değil.
- Megatron-LM: Çift GPU ile paralel eğitimde büyük dil modellerinde %15’lik bir iyileşme sağlıyor.
- NVIDIA Apex: FP16 hızlandırma ile %20 oranında iyileşme sunuyor.
Sonuç ve Öneriler
Hangi kütüphaneyi kullanmanız gerektiği, özellikle yanıt süresi ve eğitim altyapınızla ilgilidir. Flash Attention ve Xformers, dikkat hesaplamalarını hızlandırmak isteyenler için en iyi seçeneklerdir. DeepSpeed ve Megatron-LM, büyük modeller için dağıtılmış eğitimde verimli sonuçlar verir, ancak dikkat hızlandırmasında Flash Attention kadar hızlı değillerdir.
Eğer amacınız hızlı yanıt süreleri ve dikkat hesaplamalarını hızlandırmaksa, Flash Attention ve Xformers kullanmak daha verimli olacaktır. Bu kütüphaneler, özellikle RTX 4070 Ti SUPER ile uyumlu çalışarak yanıt sürelerinde %25 ila %30 arasında bir iyileşme sağlar.