

ArXiv Nedir?
ArXiv Python paketi, Cornell Üniversitesi’nin açık erişimli ön baskı arşivi arXiv.org’a programatik erişim sağlayan resmi kütüphanedir. Bu paket sayesinde milyonlarca akademik makaleye, araştırma raporuna ve ön baskıya Python kodları aracılığıyla ulaşabilirsiniz.
Temel Özellikler:
- Ücretsiz Erişim: 2+ milyon makaleye sınırsız erişim
- Gerçek Zamanlı Veri: Günlük yüklenen yeni makaleler
- Zengin Metadata: Yazar, tarih, kategori, özet bilgileri
- PDF İndirme: Tam metin makaleleri otomatik indirme
- Gelişmiş Filtreleme: Tarih, kategori, yazar bazlı arama
Kurulum:
pip install arxivArXiv ile Yapılabilecek Kapsamlar
🔍 Araştırma ve Trend Analizi
- Teknoloji Trendleri: AI, blockchain, quantum computing alanlarındaki gelişimler
- Yayın Analizi: Belirli konularda ne kadar makale yayınlandığı
- Zaman Serisi Analizi: Araştırma alanlarının popülerlik değişimi
- Anahtar Kelime Trendleri: Hangi terimlerin yükselişte olduğu
📊 Veri Bilimi ve Analytics
- Bibliyometrik Analiz: Atıf ağları ve yazar işbirlikleri
- Makine Öğrenimi: Metin sınıflandırma ve kümeleme
- Doğal Dil İşleme: Özet özetleme ve anahtar kelime çıkarma
- Görselleştirme: Araştırma haritaları ve network analizleri
🤖 AI ve Chatbot Uygulamaları
- RAG Sistemleri: Retrieval-Augmented Generation
- Akademik Asistanlar: Makale önerisi ve analiz
- Literature Review: Otomatik literatür taraması
- Research Assistant: Kişiselleştirilmiş araştırma asistanı
📚 Eğitim ve Öğretim
- Ders Materyali: Güncel araştırmaları ders içeriğine entegre etme
- Öğrenci Projeleri: Araştırma metodolojisi öğretimi
- Akademik Yazım: Referans ve kaynak yönetimi
- Tez Danışmanlığı: İlgili çalışmaları bulma ve analiz etme
💼 İş ve Strateji
- Competitive Intelligence: Rakip teknolojileri takip etme
- Patent Analizi: Benzer araştırmaları tespit etme
- R&D Planning: Araştırma yönlendirme
- Innovation Tracking: Yenilik alanlarını izleme
6. 📱 Uygulama Geliştirme
- Mobil Uygulamalar: Araştırma okuma uygulamaları
- Web Platformları: Akademik sosyal ağlar
- Browser Extensions: Hızlı makale erişimi
- API Servisleri: Üçüncü parti entegrasyonlar
ArXiv ile Yapılabilecek 5 Örnek Proje Sorusu
🔥 Trend Analizi
“2020-2025 yılları arasında ‘quantum computing’ alanında yayınlanan makalelerin sayısı nasıl değişti? Hangi alt konular daha popüler hale geldi?”
🤝 Yazar İşbirliği Ağı
“Yapay zeka alanında en çok işbirliği yapan yazarlar kimler? Bu yazarların ortak çalışma ağını görselleştirin ve en merkezi aktörleri belirleyin.”
📈 Teknoloji Öngörüsü
“Son 3 yılda ‘large language model’ konusunda yayınlanan makalelerin özetlerini analiz ederek, gelecek 2 yılda hangi alt teknolojilerin öne çıkacağını tahmin edin.”
🎯 Kişiselleştirilmiş Öneri
“Kullanıcının araştırma geçmişi ve ilgi alanlarına göre her hafta en alakalı 10 makaleyi öneren bir sistem geliştirin. Kullanıcı feedback’i ile önerileri nasıl iyileştirirsiniz?”
🌍 Global Araştırma Haritası
“Ülkeler bazında hangi araştırma alanlarında daha güçlü? Yazarların kurumsal bağlantılarını kullanarak global araştırma işbirliği haritasını çıkarın ve Türkiye’nin konumunu analiz edin.”
🌍 Kendi Deneyimim:
ArXiv’deki güncel makaleleri otomatik olarak analiz eden ve kullanıcı sorularını yanıtlayan bir AI sistemi geliştirmeye başladım. Sistem, kullanıcının sorduğu sorudan (örneğin “2025’te makine öğrenmesinde ne gibi ilerlemeler var?”) sorusundan o soruya ait anahtar kelimeleri otomatik çıkarıyor, ArXiv API’si üzerinden ilgili makaleleri arıyor ve bu makalelerin özetlerini vektör veritabanında saklıyor. Ardından, LangChain’in RAG yaklaşımını kullanarak, yerel Ollama LLM modelim ile bu makalelerden elde edilen bilgileri harmanlayarak kullanıcıya Türkçe cevap verir. Sadece bir soru sorarak hem güncel araştırmaları keşfedebilir hem de bu araştırmaların özetini ve kaynaklarını elde edebiliyorum. (kişisel bir akademik araştırma asistanına sahip olmak gibi)
Çıktı Örneği:
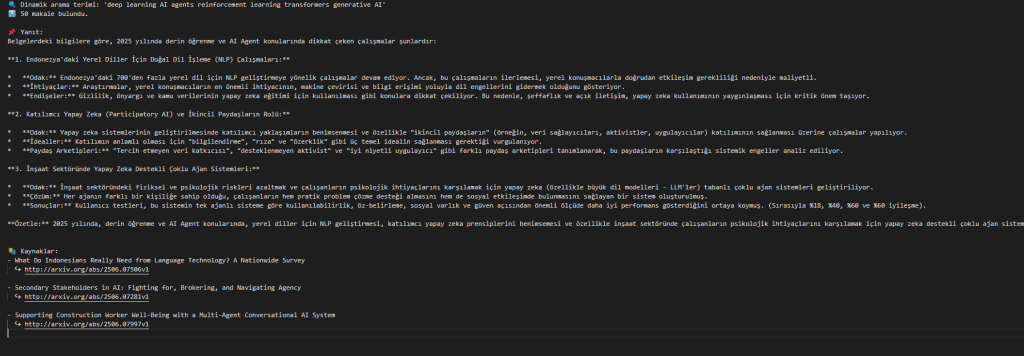
Soru= “Derin öğrenme ve AI Agent konularında 2025 yılında yapılan dikkat çeken çalışmalar var mı, nelerden bahsediliyor?”
🔍 Dinamik arama terimi: ‘deep learning AI agents reinforcement learning transformers generative AI’
📊 50 makale bulundu.
📌 Yanıt:
Belgelerdeki bilgilere göre, 2025 yılında derin öğrenme ve AI Agent konularında dikkat çeken çalışmalar şunlardır:
1. Endonezya’daki Yerel Diller İçin Doğal Dil İşleme (NLP) Çalışmaları:
- Odak: Endonezya’daki 700’den fazla yerel dil için NLP geliştirmeye yönelik çalışmalar devam ediyor. Ancak, bu çalışmaların ilerlemesi, yerel konuşmacılarla doğrudan etkileşim gerekliliği nedeniyle maliyetli.
- İhtiyaçlar: Araştırmalar, yerel konuşmacıların en önemli ihtiyacının, makine çevirisi ve bilgi erişimi yoluyla dil engellerini gidermek olduğunu gösteriyor.
- Endişeler: Gizlilik, önyargı ve kamu verilerinin yapay zeka eğitimi için kullanılması gibi konulara dikkat çekiliyor. Bu nedenle, şeffaflık ve açık iletişim, yapay zeka kullanımının yaygınlaşması için kritik önem taşıyor.
2. Katılımcı Yapay Zeka (Participatory AI) ve İkincil Paydaşların Rolü:
- Odak: Yapay zeka sistemlerinin geliştirilmesinde katılımcı yaklaşımların benimsenmesi ve özellikle “ikincil paydaşların” (örneğin, veri sağlayıcıları, aktivistler, uygulayıcılar) katılımının sağlanması üzerine çalışmalar yapılıyor.
- İdealler: Katılımın anlamlı olması için “bilgilendirme”, “rıza” ve “özerklik” gibi üç temel idealin sağlanması gerektiği vurgulanıyor.
- Paydaş Arketipleri: “Tercih etmeyen veri katkıcısı”, “desteklenmeyen aktivist” ve “iyi niyetli uygulayıcı” gibi farklı paydaş arketipleri tanımlanarak, bu paydaşların karşılaştığı sistemik engeller analiz ediliyor.
3. İnşaat Sektöründe Yapay Zeka Destekli Çoklu Ajan Sistemleri:
- Odak: İnşaat sektöründeki fiziksel ve psikolojik riskleri azaltmak ve çalışanların psikolojik ihtiyaçlarını karşılamak için yapay zeka (özellikle büyük dil modelleri – LLM’ler) tabanlı çoklu ajan sistemleri geliştiriliyor.
- Çözüm: Her ajanın farklı bir kişiliğe sahip olduğu, çalışanların hem pratik problem çözme desteği almasını hem de sosyal etkileşimde bulunmasını sağlayan bir sistem oluşturulmuş.
- Sonuçlar: Kullanıcı testleri, bu sistemin tek ajanlı sisteme göre kullanılabilirlik, öz-belirleme, sosyal varlık ve güven açısından önemli ölçüde daha iyi performans gösterdiğini ortaya koymuş. (Sırasıyla %18, %40, %60 ve %60 iyileşme).
Özetle: 2025 yılında, derin öğrenme ve AI Agent konularında, yerel diller için NLP geliştirmesi, katılımcı yapay zeka prensiplerini benimsemesi ve özellikle inşaat sektöründe çalışanların psikolojik ihtiyaçlarını karşılamak için yapay zeka destekli çoklu ajan sistemleri oluşturulması gibi önemli çalışmalar yapıldığı görülüyor. Bu çalışmalar, yapay zekanın daha kapsayıcı, şeffaf ve insan odaklı bir şekilde geliştirilmesine katkıda bulunmayı amaçlıyor.
📚 Kaynaklar:
- What Do Indonesians Really Need from Language Technology? A Nationwide Survey
↪ http://arxiv.org/abs/2506.07506v1 - Secondary Stakeholders in AI: Fighting for, Brokering, and Navigating Agency
↪ http://arxiv.org/abs/2506.07281v1 - Supporting Construction Worker Well-Being with a Multi-Agent Conversational AI System
↪ http://arxiv.org/abs/2506.07997v1