
Algoritmalar Arasında Bir Kıyas: Apriori, Eclat, Dclat, FP-Growth, AprioriTID, Relim ve H-Mine ile İlişkilendirme Kuralı Madenciliği
Giriş:
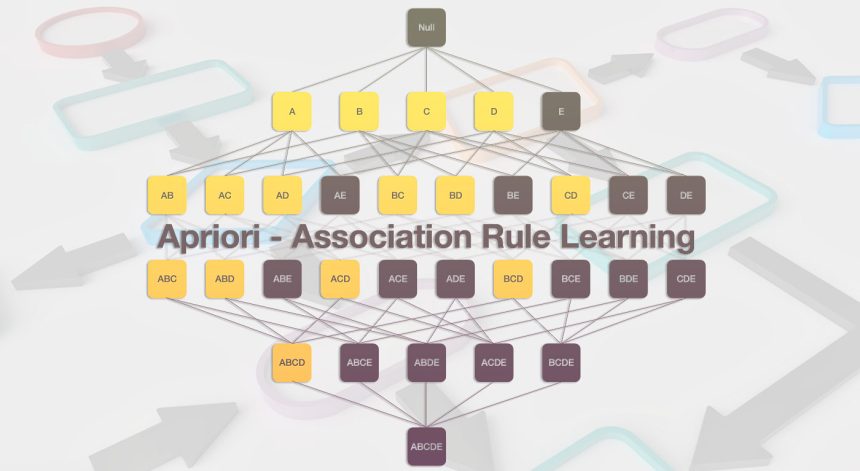
Birliktelik kuralı madenciliği, veri setlerindeki gizli ilişkileri keşfetme amacı taşıyan kritik bir veri analizi metodudur. Bu alandaki temel algoritmalar, farklı veri yapılarına ve problem alanlarına yönelik benzersiz yaklaşımlarıyla dikkat çekmektedir. Bu yazımda, Apriori, Eclat, Dclat, FP-Growth, AprioriTID, Relim ve H-Mine algoritmalarını detaylı bir şekilde inceleyerek, ilişkilendirme kuralı madenciliğindeki çeşitliliği ve bu algoritmaların karşılaştırmalı analizini sunmayı amaçladım. İlişkilendirme kuralı madenciliği, özellikle e-ticaret, perakende, pazarlama ve öneri sistemleri gibi birçok uygulama alanında yaygın olarak kullanılmaktadır.
Bu algoritmaları benimseyen küresel büyük oyunculardan birkaç örnek:
- Amazon: Müşteri davranışlarını analiz ederek kişiselleştirilmiş alışveriş önerileri sunan Amazon, birliktelik kuralı madenciliği algoritmalarını etkili bir şekilde kullanmaktadır.
- Netflix: İzleme geçmişlerini değerlendirerek kullanıcılara özel film ve dizi önerileri sunan Netflix, birliktelik kuralı madenciliğini içerik önerilerinde kullanmaktadır.
- Google: Arama geçmişi ve kullanıcı tercihleri üzerinden kişiselleştirilmiş reklam hedeflemesi ve arama sonuçları sunan Google, birliktelik kuralı madenciliği prensiplerinden faydalanmaktadır.
- Alibaba: E-ticaret devi Alibaba, kullanıcıların alışveriş alışkanlıklarını analiz ederek öneri sistemlerini güçlendirmekte ve birliktelik kuralı madenciliği algoritmalarını kullanmaktadır.
- Walmart: Perakende sektöründe lider olan Walmart, müşteri davranışlarını anlamak ve öneri sistemlerini geliştirmek için birliktelik kuralı madenciliği algoritmalarını kullanmaktadır.
Algoritmaların Temel Farkları:
- Apriori:
- Çalışma Prensibi: Frekanslı itemset’leri bulmak için geniş bir tarama ve birleştirme aşaması içerir.
- Veri Yapısı: Dikey bir veri yapısı kullanır.
- Uygulama Alanları: Genel kullanım için uygundur, özellikle yüksek yoğunluklu itemset’leri keşfetmeye odaklanır.
- Eclat ve Dclat:
- Çalışma Prensibi: Dikey yapıda daha etkili itemset’leri bulma üzerine odaklanır.
- Veri Yapısı: Dikey bir veri yapısı kullanır.
- Uygulama Alanları: Daha hızlı performans ve düşük yoğunluklu itemset’lerin analizi için uygun.
- FP-Growth:
- Çalışma Prensibi: Sık itemset’leri ağaç yapısı içinde bulur, Apriori’ye göre daha hızlı çalışabilir.
- Veri Yapısı: Veriyi ağaç yapısı içinde temsil eder.
- Uygulama Alanları: Büyük veri setleri üzerinde hızlı performans göstermek istendiği durumlar için ideal.
- FIN ve AprioriTID:
- Çalışma Prensibi: Özel yapıları kullanarak veriyi analiz eder, diğer algoritmaların özelliklerini birleştirir.
- Veri Yapısı: Özel tasarlanmış yapıları kullanır.
- Uygulama Alanları: Belirli durumlar için optimize edilmiş performans sağlar.
- Relim:
- Çalışma Prensibi: Yatay veri yapısında sık itemset’leri bulur.
- Veri Yapısı: Yatay bir veri yapısı kullanır.
- Uygulama Alanları: Yatay yapıda etkili performans ve belirli durumlar için uygun.
- H-Mine:
- Çalışma Prensibi: Hem dikey hem de yatay madencilik aşamalarını içerir.
- Veri Yapısı: Yatay bir veri yapısı üzerinde odaklanır.
- Uygulama Alanları: Düşük yoğunluklu itemset’leri bulma konusunda avantajlı.
Algoritmaların Kullanım Alanları:
Apriori ve Eclat:
- Perakende Sektörü:
- Tüketici alışveriş alışkanlıklarını analiz ederek, bir müşterinin bir ürünü satın alması durumunda diğer ürünleri önerme.
- Ürün yerleştirme stratejilerini optimize etme.
- Pazarlama ve Satış:
- Kampanya planlaması ve müşteri segmentasyonu için kullanılma.
- Etkili çapraz satış stratejileri geliştirme.
- Telekomünikasyon:
- Müşteri kullanım modellerini anlayarak, öneri sistemleri oluşturma.
- Hizmet paketlerini optimize etme.
FP-Growth:
- Büyük Veri Analizi:
- Büyük veri setleri üzerinde etkili bir şekilde çalışabilme avantajı.
- İnternet trafiği analizi, kullanıcı davranışlarını anlama.
- Finans ve Sigorta:
- Müşteri harcama alışkanlıklarını analiz ederek, kişiselleştirilmiş finansal önerilerde bulunma.
- Kredi riski değerlendirmesi ve dolandırıcılık tespiti.
- Sağlık Sektörü:
- Hastalık teşhisi ve tedavi planlaması için hastalık ilişkilerini anlama.
- İlaç etkileşim analizi.
H-Mine:
- Düşük Yoğunluklu Veri Setleri:
- E-ticarette nadir satılan ürünleri keşfetme ve önerme.
- Kullanıcıların genellikle göz ardı ettiği ürün ilişkilerini analiz etme.
- Haber ve Medya:
- Kullanıcıların genellikle birlikte tükettiği içerikleri belirleme.
- Yeni içerik önerilerinde bulunma.
Diğerleri (AprioriTID, Relim):
Bu algoritmalar, özel durumlar için tasarlanmış olup, genellikle belirli veri seti yapıları veya madencilenecek ilişkilerin özellikleri için optimize edilmiştir. Örneğin, AprioriTID, Apriori’nin bir türevidir ve transaksiyon ID’leri ile çalışarak belirli bir türdeki ilişkileri analiz etmeye odaklanır.
Her algoritmanın avantajları ve dezavantajları vardır ve kullanılmak istenen uygulama alanına bağlı olarak seçilmelidir. İlişkilendirme kuralı madenciliği algoritmaları genellikle müşteri davranış analizi, öneri sistemleri, stok yönetimi ve pazarlama stratejileri gibi birçok alanda kullanılabilir.
Association Rules Python Örnekleri:
Apriori Algoritması
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
# Örnek bir veri seti
transactions = [
['elma', 'ekmek', 'süt'],
['elma', 'süt'],
['ekmek', 'peynir'],
['elma', 'ekmek', 'süt', 'peynir'],
['ekmek', 'süt', 'peynir']
]
# Veri setini uygun formata dönüştürme
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)
# Frequent itemsets bulma
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
# Association rules oluşturma
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
# Sonuçları gösterme
print("Frequent Itemsets:")
print(frequent_itemsets)
print("\nAssociation Rules:")
print(rules)
FP-Growth Algoritması
from mlxtend.frequent_patterns import fpgrowth
import pandas as pd
# Örnek bir veri seti
transactions = [
['elma', 'ekmek', 'süt'],
['elma', 'süt'],
['ekmek', 'peynir'],
['elma', 'ekmek', 'süt', 'peynir'],
['ekmek', 'süt', 'peynir']
]
# Veri setini uygun formata dönüştürme
df = pd.DataFrame(transactions)
# Frequent itemsets bulma
frequent_itemsets = fpgrowth(df, min_support=0.4, use_colnames=True)
# Sonuçları gösterme
print("Frequent Itemsets:")
print(frequent_itemsets)
H-Mine Algoritması
from itertools import combinations
def generate_hmine_candidates(data, min_support):
candidates = set()
item_counts = {}
# Frekansları sayma
for transaction in data:
for item in transaction:
if item in item_counts:
item_counts[item] += 1
else:
item_counts[item] = 1
# Düşük yoğunluklu itemset'leri aday olarak seçme
for item, count in item_counts.items():
if count >= min_support:
candidates.add((item,))
# Adayları birleştirme
for i in range(2, len(candidates) + 1):
for combination in combinations(candidates, i):
combined_set = set()
for itemset in combination:
combined_set.update(itemset)
if len(combined_set) == i and all(item_counts[item] >= min_support for item in combined_set):
candidates.add(tuple(sorted(combined_set)))
return candidates
# Örnek veri seti
data = [
['elma', 'ekmek', 'süt'],
['elma', 'süt'],
['ekmek', 'peynir'],
['elma', 'ekmek', 'süt', 'peynir'],
['ekmek', 'süt', 'peynir']
]
# Minimum destek değeri
min_support = 2
# H-Mine adaylarını bulma
hmine_candidates = generate_hmine_candidates(data, min_support)
# Sonuçları gösterme
print("H-Mine Adayları:")
print(hmine_candidates)
AprioriTID
from pymining import itemmining, assocrules
# Örnek veri seti
transactions = [
['elma', 'ekmek', 'süt'],
['elma', 'süt'],
['ekmek', 'peynir'],
['elma', 'ekmek', 'süt', 'peynir'],
['ekmek', 'süt', 'peynir']
]
# Veri setini uygun formata dönüştürme
transaction_db = itemmining.get_tids_from_transactions(transactions)
# AprioriTID algoritması kullanma
item_sets = itemmining.apriori(transaction_db, target='a', supp=2)
# Sonuçları gösterme
print("AprioriTID Itemsets:")
print(item_sets)
Relim
from pymining import itemmining, assocrules
# Örnek veri seti
transactions = [
['elma', 'ekmek', 'süt'],
['elma', 'süt'],
['ekmek', 'peynir'],
['elma', 'ekmek', 'süt', 'peynir'],
['ekmek', 'süt', 'peynir']
]
# Veri setini uygun formata dönüştürme
transaction_db = itemmining.get_tids_from_transactions(transactions)
# Relim algoritması kullanma
item_sets = itemmining.relim(transaction_db, min_support=2)
# Sonuçları gösterme
print("Relim Itemsets:")
print(item_sets)
Eclat
from pymining import itemmining, assocrules
# Örnek veri seti
transactions = [
['elma', 'ekmek', 'süt'],
['elma', 'süt'],
['ekmek', 'peynir'],
['elma', 'ekmek', 'süt', 'peynir'],
['ekmek', 'süt', 'peynir']
]
# Veri setini uygun formata dönüştürme
transaction_db = itemmining.get_tids_from_transactions(transactions)
# Eclat algoritması kullanma
item_sets = itemmining.eclat(transaction_db, min_support=2)
# Sonuçları gösterme
print("Eclat Itemsets:")
print(item_sets)
Sonuç:
İlişkilendirme kuralı madenciliği, bu çeşitli algoritmalar arasında bir denge kurmayı gerektirir. Apriori, Eclat, Dclat, FP-Growth, AprioriTID, Relim ve H-Mine algoritmaları, belirli uygulama senaryolarında daha etkili olabilir. Bu kıyas, her bir algoritmanın avantajlarını ve dezavantajlarını vurgulayarak, doğru seçimin veri seti ve hedeflenen ilişkilerin özelliklerine bağlı olarak yapılmasına yardımcı olmayı amaçlamaktadır.